Introduction
Transformer (self-attention) has a very important place in natural language processing and has been introduced in numerous models such as BERT and GPT. The success in natural language processing has led to research efforts to introduce the Transformer in computer vision tasks as well. Models comparable to the convolutional neural nets that have supported the success of deep learning in the computer vision domain are also emerging. However, for engineers who recognize that convolutional neural nets provide sufficient performance, they are not sure whether they should move on from the fundamental “convolution” layer to the next stage. In general, it is said that training a Transformer requires a great deal of data. However, this depends on the conditions, the diversity of the data, and the availability of prior learning (which I would like to try in the future). So, let’s consider the joy of using Transformer from a mathematical interpretation, and consider the advantages of introducing Transformer into your project.
Self-Attention
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
https://arxiv.org/abs/2010.11929
The self-attention used for Transformer is shown in the figure below. The image is decomposed into patches of fixed size, followed by vector and linear transformation. After linear transformation, the vector X incorporating Position Embedding is used to compute Queue, Key, and Value.
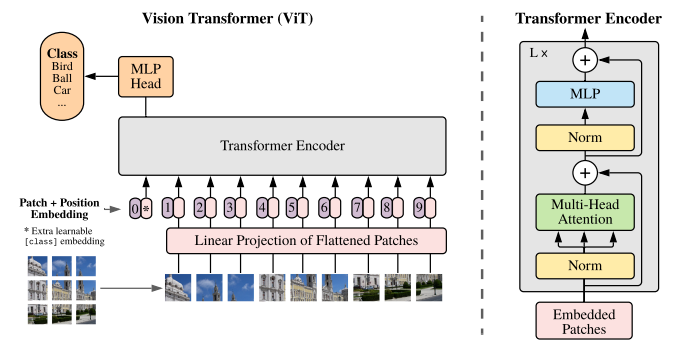
Simplified formulations are shown in (1) – (5)
\begin{align}
Q = XW_q \\
K = XW_k \\
V = XW_v \\
\end{align}The reference A is obtained from the matrix product of Queue and Value and the Softmax function, and this A is used to obtain the output Z of the Attention Head.
\begin{align}
A = softmax(QK^T/\sqrt{d}) \\
Z = AV
\end{align}Equation (5) can be expanded as follows.
\begin{align}
Z = AXW_v \\
Z = D^{-1}AXW_v \\
\end{align}What does equation (7) mean? Where have you seen it before? If you are interested in combinatorial problems you might know. Apparently, this is the same as the graph convolution formula. In other words, this formula can be interpreted as dynamically changing the adjacency matrix A (which defines the connections between nodes) depending on the input image and convolving the features between the nodes.
Let’s take a look at an example graph: there are three nodes, two of which are connected by undirected edges.
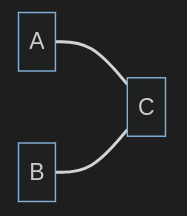
To represent this graph (and convolution) , 3 matrices are defined.
\begin{align}
D = \begin{pmatrix}
1, 0, 0 \\
0, 1, 0 \\
0, 0, 2 \\
\end{pmatrix} \\
A^e = \begin{pmatrix}
0, 0, 1 \\
0, 0, 1 \\
1, 1, 0 \\
\end{pmatrix} \\
F^e=XW^e \in \R^{3{\times}f} \\
\end{align}Let’s say these nodes also have features, which we denote by X. Also, let W be the weight for extracting features from X. The graph convolution is
\begin{align}
X_{l+1}={D^{-1}}A^eF^e={D^{-1}}A^eX_{l}W^e \\
\end{align}Since equations (7) and (11) share a common form, we can interpret self-attention as one form of graph convolution. Thus, we can say that self-attention is extracting n feature combinations between nodes (patch features in the vision task) and their features.
In terms of this feature, what is the advantage of using self-attention?
What is the advantage of using Transformer?
Understanding Images with Context
Before looking at the advantages of SELF-ATTENTION, let’s have a look at the characteristics of convolutional neural nets. Convolutional neural nets extract local features in the convolutional region. As shown in the figure below, the more layers, the wider the receptive field. It can also be said that the pooling layer widens this range. Thus, image understanding is performed by successfully aggregating local features.
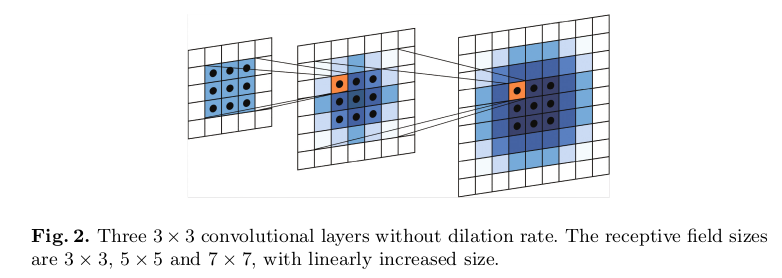
This site gets a good reference to know the receptive field of your model.
https://jojonki.github.io/Vis-Receptive-Fields/
While this model has been very successful in the image recognition domain, we can also envision situations where recognition becomes difficult. For example, when features are far from each other and their context must be understood.
Consider the following photo, a situation where the features of the object (bird) you want to recognize are only in a small area and are redundant, like the background (sky), but the context in which the background and object are reflected is not well recognized. Often, the convolutional neural network may not recognize the object well because of the distance between the background and the object.
If it does not understand the background information, it may not be able to recognize the small bird.
Since graph convolution-based neural nets were expected to solve this situation, Transformer may be able to solve these situations. Attention is said to be able to recognize images with a wide field of view even with a relatively shallow layer model structure.

Attention Map Visualization
Attention-Rollout enables us to visualize its “attention”.
What is the disadvantage of using Transformer?
Transformer may be overkill if you want to solve a task where image recognition can be done successfully using only local features.
Reference
[1]AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
[2]Ye Luo, Tongji University: MC-DCNN: Dilated Convolutional Neural Network for Computing Stereo
[3]Samira Abnar, Willem Zuidema Quantifying Attention Flow in Transformers in https://arxiv.org/abs/2005.00928