https://arxiv.org/abs/2104.14294
About
DINO is a self-supervised learning algorithm that can be applied to CNNs and ViTs. While it employs a bootstrapping-like approach, self-supervised learning is known for its higher generality and stricter constraints since it learns without any annotations. It is used for transfer learning in downstream tasks such as image classification and segmentation. In OpenAI CLIP, contrastive learning is utilized to train on text and image pairs, using text as auxiliary data. On the other hand, DINO is trained using the identities of positive pairs. DINO employs a technique known as “distillation,” which was popular in the past. However, it differs from traditional distillation in that it does not perform distillation on a pre-trained network but instead utilizes a model that is not pre-trained from scratch as the teacher network.
Keywords
- self-supervised learning
- Distillation
- Centering
- Sharpning
- Exponential Moving Average
Distillation on DINO Training
The learning process used in DINO is a process similar to SimCLR. It involves creating positive sample pairs using image augmentation and then training both a teacher and a student network. DINO applies centering operations to the network’s outputs. This is done to prevent the network from producing the same output for all inputs. Below is an overview of the learning process and pseudocode as described in the paper
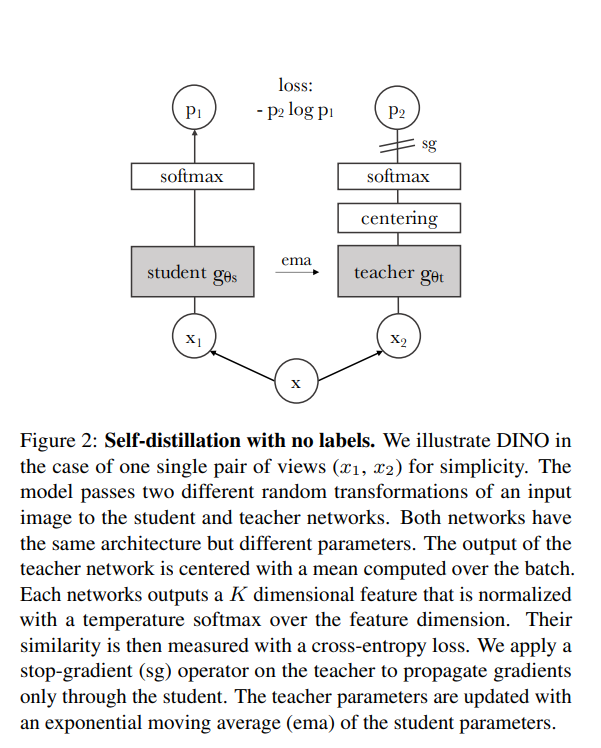

During the optimization process in DINO, there are several techniques and considerations employed:
- Temperature-scaled Softmax: The use of temperature-scaled softmax helps emphasize certain probability values. By introducing a temperature parameter (T, where T >= 1), you can control the “softness” of the probability distribution generated by the softmax function. Higher values of T make the distribution softer, emphasizing the relative differences in probabilities between classes. This can be particularly useful in fine-tuning the network’s sensitivity to certain patterns or features.
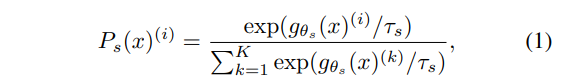
- Exponential Moving Average for Weight Parameter Updates: To stabilize the network’s output during training and improve representation learning, DINO employs an exponential moving average (EMA) when updating the weight parameters. EMA helps in maintaining a smoother and more stable representation of the network’s parameters over time. It reduces the effect of sudden fluctuations and noise in parameter updates, which can lead to more robust convergence. Additionally, the use of EMA for parameter updates can enable model ensembling, which combines multiple snapshots of the model’s parameters during training. This ensemble can enhance the model’s representation capacity and potentially lead to better generalization.

These techniques collectively contribute to the effectiveness of DINO’s self-supervised learning process and help in achieving more robust and improved representations without the need for annotated data.
Visualize Attention Map
