XGBoost
XGBoost is based on gradient boosting trees, it excels in computational efficiency, flexibility, and features. It is a model commonly used in machine learning competitions.
https://arxiv.org/abs/1603.02754
Loss Function and Regularization
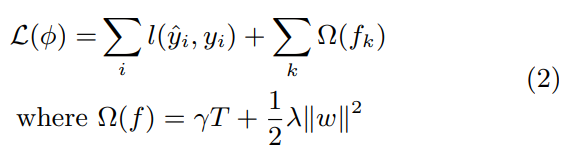
The T represents the number of terminal nodes. The variable w is a vector that contains the values of all leaf nodes, which are the average values of y for the samples in each leaf node. γ and λ are hyperparameters.
In other words, XGBoost is a modification of gradient boosting trees, optimized by adding a regularization term to the original loss function.