About
SAC (Soft Actor-Critic) is a reinforcement learning algorithm that integrates elements of Q-learning (value-based learning) into the policy gradient method (Actor-Critic framework). Specifically, it adopts the framework of maximum entropy reinforcement learning, promoting exploration by considering not only standard rewards but also the entropy of the policy (action diversity).
At first glance, policy gradient methods may seem to have a significant advantage over Q-learning. As I mentioned in a previous article, optimizing the advantage allows direct learning of action values from specific states. However, in practical applications, policy gradient methods have some weaknesses.
These include “high variance in gradients,” “poor sample efficiency,” and “overly deterministic policies.” These issues primarily arise because on-policy methods cannot reuse past data, which leads to frequent shifts in the data distribution and unstable learning. Although increasing the number of parallel environments can help collect more diverse samples in each update, it does not fundamentally solve the problem since the algorithm still relies only on the latest samples for learning.
This is why SAC, as an off-policy method, is advantageous—it can utilize past data efficiently, reducing gradient variance and improving sample efficiency.
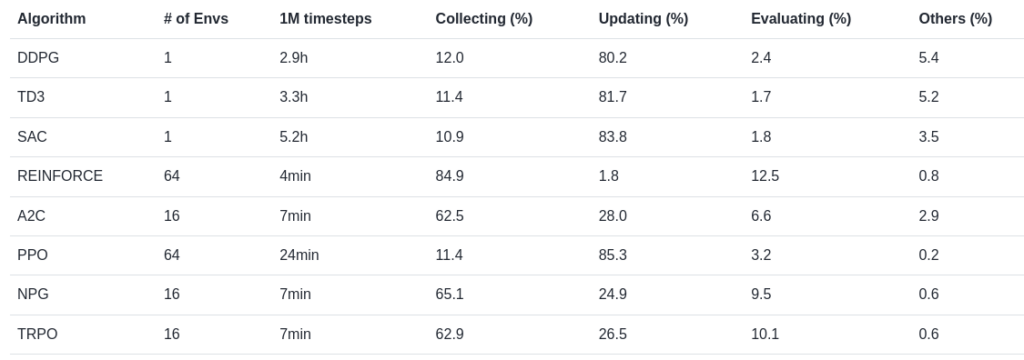
Benchmark in Tianshou using MuJoCo
You can see the MuJoCo benchmarks on the tutorial page of Tianshou.
SAC shows good results in many tasks. The only exception seems to be Swimmer, where its performance is not very impressive.
https://tianshou.org/en/stable/01_tutorials/06_benchmark.html
A more interesting aspect is the benchmark table showing the computation time.
Compared to other methods, SAC requires a significant amount of time—5 hours per 1M timesteps. Around 80% of this time is spent mainly on learning updates, which seems to be a disadvantage. While SAC has good sample efficiency, it takes longer to train as a trade-off.
This suggests that SAC may not be the best choice as an initial option, especially for simple tasks.
Most likely, the long training time is due to SAC having two Q-functions, a policy, and the need to repeatedly train on data stored in the replay buffer.
Ran SAC with Humanoid-v3 in MuJoCo
When I studied reinforcement learning in the past, I tested A3C on Humanoid. But it didnt train at all.
Sometimes, it seemed to take a few steps, nevertheless, it kept hopping and falling over repeatedly(even though it is not a hopper😂). It was probably due to poor sample efficiency.
Anyway, with the emergence of many frameworks like Tianshou and Ray, it has become easy to experiment with RL nowadays. So, I decided to try SAC.
The device I used is here
NVIDIA GeForce GTX 1660
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7The process occupies only 128MiB of GPU for Ant-v4 and Humanoid-v4 . This is good since the requirements for GPU device is not so big.
And what great is that MuJoCo is completely free these days!!!
It costs around $1500 a year previously. I used it as student license, or something by free, Still, I felt a psychological burden.

Experiments
The observation and action data is like this
Ant-v4
Observations shape: (17,)
Actions shape: (8,)
Action range: -1 1Humanoid-v4
Observations shape: (376,)
Actions shape: (17,)
Action range: -0.4 0.4It takes 1:20 for 10000 env_steps in my environment.
I roughly estimated that it would take about 3 hour to obtain a result that would be reasonably satisfying.
Please wait just a minutes…
Result: Humanoid-v4
Initially, his policy is like below video, it seems that it is just falling down.
But lastly, this result is obtained.
the action itself is a bit far from my intention(not walking), but it is proceeding to straight direction. Even though this result looks not so great, it is difficult to get this level of performance using A3C actually. It only? takes 5 hours!
Change discount rate
Since, his action looks quite moderate and not taking exploration so much in the previous experiment, I changed discount rate 0.99 to 0.96 in the training process. It looks more of walking!