https://arxiv.org/pdf/2005.14165
This paper is very interesting in the sense that it provides valuable insights into how to utilize the foundational model for real-world problems. In most machine learning tasks, we have followed the procedure of preparing a dataset, training a model on that problem, and then predicting on new data. However, there is a possibility that how to solove these downstream tasks may be changed.
The impact of few-shot learning as context
The following is a quoted figure from the paper. As context (example sentences) are progressively provided in the prompt (X-axis), it illustrates how Accuracy changes over number of examples.
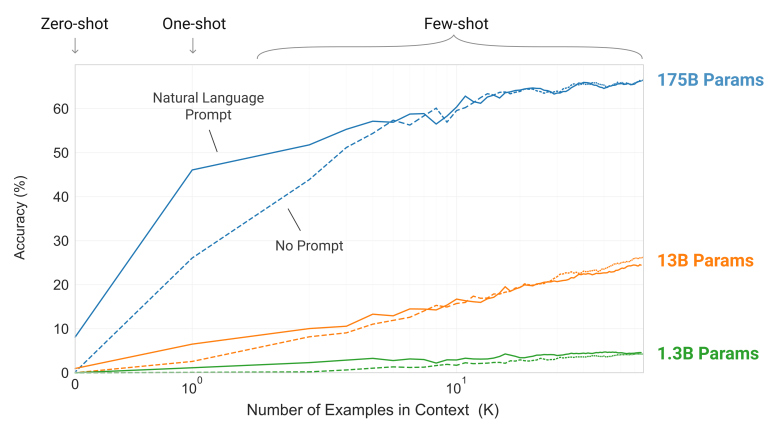
In models with a large number of parameters, you can observe that performance improves as you increase the context. This suggests that if you can somehow identify the appropriate context, there is a higher likelihood of generating the desired text. Consequently, this indicates the potential for solving tasks more easily using techniques like open-book question answering, and traditional retraining methods such as fine-tuning might risk compromising usability.
Are large-scale language models like ChatGPT useless because they are prone to lying?
No, absolutely Not.
As indicated above, a crucial aspect of utilizing large-scale language models as foundational models is not that the model itself provides inaccurate responses, but rather its capacity to solve problems. In other words, despite the potential for generating inaccurate responses due to hallucinatory effects when used in a zero-shot manner, accuracy can be enhanced through few-shot learning. The goal is to address various tasks such as summarization, translation, brainstorming, leveraging context for resolution. With this problem-solving capability, the model can adapt to diverse contexts without requiring retraining for each context.
The Open-book Question Answering System is a notable example of an application that leverages few-shot learning effectively.
Open-book Question Answering
Open-book Question Answering is a type of problem where you answer questions by referring to a textbook. Since the answers are provided in the textbook, as long as you can search for the relevant section pertaining to the question, you can relatively easily provide an answer.
Therefore, the issue becomes a matter of searching. How can we perform this search? A common approach is to use text Embedding. Text Embedding involves representing textual features as vectors and employing measures like cosine similarity to retrieve for similar information.For conducting vector searches of desired information from vast amounts of text and text embeddings, using a Vector Database proves highly convenient. Vector Databases such as Qdrant, Milvus, and Weaviate are available for this purpose. Additionally, there are other search engines and databases like Elasticsearch and Redis that also offer the capability to perform vector search, apart from Vector Databases.
These vector databases not only come with client libraries but also offer REST APIs, allowing them to be invoked from tools like LangChain.
The potential for business expansion of open-book question-answering applications
By consolidating specialized knowledge into textual form and casually registering it in a Vector Database, information retrieval becomes feasible. Unlike conventional keyword searches, there is an advantage of enabling ambiguous searches. For instance, there are numerous similar words in the world. In keyword searches, even similar words won’t yield results if their spellings differ. However, neural search potentially offers the capability to overcome this limitation.
Furthermore, once specialized knowledge is registered in the Vector Database, large-scale language models can respond to client queries as if they were experts. Previously, accessibility of intricate knowledge was confined to specialists. However, the amalgamation of large-scale language models and search has the potential to revolutionize societal structures. This could make knowledge accessible to all without relying on doctors, lawyers, accountants, engineers, to researchers. Their (our) professions represent substantial costs for society. Acquiring their specialized knowledge and skills requires significant time and education. Of course, this doesn’t render experts obsolete. Nonetheless, accessibility to their knowledge could undergo significant transformation.
The transformation of societal structures presents perhaps the most rewarding endeavor for engineers and entrepreneurs. Even if it is considered disruptive to some, could there be a more fulfilling profession?
Is there a more fulfilling profession for engineers and entrepreneurs as society’s framework shifts? Even if this were to be disruptive for someone.