Conclusion
Siamese Networks and SimCLR are both different machine learning architectures used to learn features of objects, but they employ distinct approaches.
Siamese Networks focus on comparing pairs of objects, determining whether they belong to the same class or not. Their primary purpose is to evaluate similarity or dissimilarity.
SimCLR, on the other hand, is a form of self-supervised learning that learns from large unlabeled datasets. It takes two different data augmentations of the same image as input and treats them as belonging to the same class. It is primarily suited for a wide range of computer vision tasks such as image recognition, semantic segmentation, and feature extraction for pre-training.
Siamese Networks take pairs as input to decide if they belong to the same class, with a primary aim of assessing similarity or dissimilarity. It appears to have been researched with a view to applications such as facial ID authentication.
SimCLR, a form of self-supervised learning, leverages large unlabeled datasets for training. It takes two distinct data augmentations of the same image as input and treats them as belonging to the same class. It is mainly used for various computer vision tasks like image recognition, semantic segmentation, and pre-training feature extraction.
SimCLR
https://arxiv.org/pdf/2002.05709.pdf
The scheme being employed here is very simple. It involves transforming images through Data Augmentation and then training on the similarity between the features of these transformed images. If the source is the same, the similarity is high; if it’s different, the similarity is low.
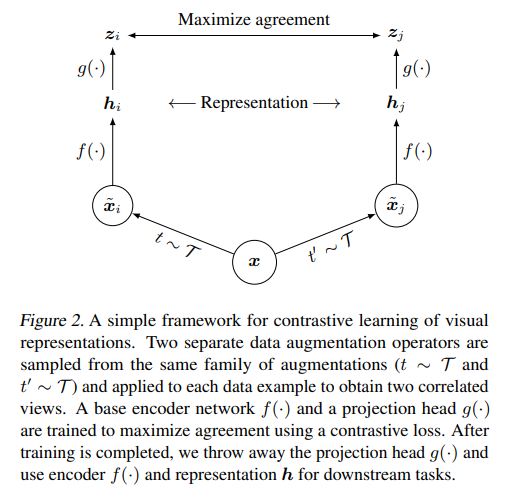
According to the paper:
(1) It demonstrates the importance of combining data augmentations in defining effective predictive tasks, (2) it shows that introducing a learnable nonlinear transformation between the representation and the contrastive loss significantly improves the quality of the learned representations, and (3) it indicates that contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning. It can considerably outperform previous methods for self-supervised and semi-supervised learning on ImageNet. A linear classifier trained on self-supervised representations learned by SimCLR achieves a top-1 accuracy of 76.5%, which is a 7% relative improvement over the previous state-of-the-art, matching the performance of a supervised ResNet-50. When fine-tuned with only 1% of the labels, it achieves a top-5 accuracy of 85.8%, surpassing AlexNet with 100 times fewer labels.
論文によると (1) データ拡張の組み合わせが予測タスクの定義において重要な役割を果たしていることを示し、(2) 表現と対照的な損失の間に学習可能な非線形変換を導入することが、学習された表現の品質を大幅に向上させることを示し、(3) 対照的な学習は、教師あり学習と比較してより大きなバッチサイズとより多くのトレーニングステップから利益を得ることができることを示しています。 ImageNetにおける自己教師ありおよび半教師あり学習の以前の方法を大幅に上回ることができます。SimCLRによって学習された自己教師あり表現にトレーニングされた線形分類器は、76.5%のトップ-1精度を達成し、これは以前の最先端を上回る7%の相対的な向上であり、教師ありResNet-50の性能に匹敵します。1%のラベルのみでファインチューンされた場合、85.8%のトップ-5精度を達成し、ラベル数が100倍少ないAlexNetを上回ります。
Oh? Wait… Is this framework quite close to Siamese Newtwork?
Siamese Newtwork
https://en.m.wikipedia.org/wiki/Siamese_neural_network
according to this page, what Siamese Network is doing is not so different from SimCLR.
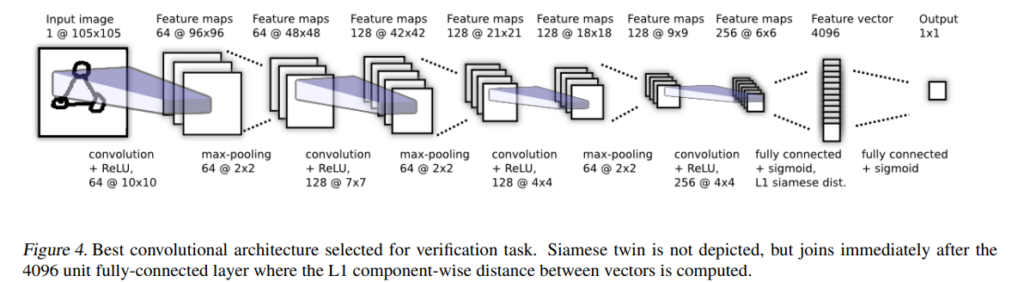
Loss Function
SimCLR

SimCLR trains similarities of embedding.
Siamese Newtwork

In Siamese Network training process , distance metrics like triplet loss or contrastive loss between 2 samples is used.