
https://arxiv.org/pdf/2104.04015.pdf
In the paper, they refer to it as self-supervised learning, but in reality, I believe it’s more like supervised learning. (I don’t necessarily see this as a bad thing, as I will explain later.)
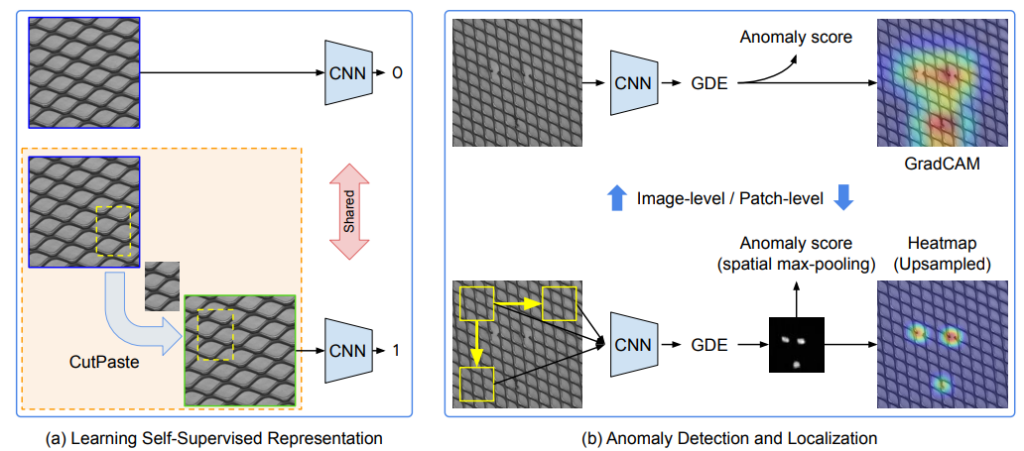
At a certain exhibition, I came across someone presenting this anomaly detection algorithm, and I was intrigued, so I decided to read about it. What it does is quite straightforward. Essentially, it generates pseudo-anomalous images by cutting and pasting parts of images and then uses supervised learning. It’s very simple, isn’t it? Because it goes through the very basic process of supervised learning, it seems to operate reliably.
One of the challenges in anomaly detection is that defining what constitutes an anomaly can be difficult. Many methods implicitly incorporate their own definitions into the model. However, this approach seems to have an advantage in that it explicitly defines anomalies with data.
The data visualization of anomalies and normalcy using T-SNE is also fascinating. While the cut-and-paste images may not closely resemble the actual anomaly data, they do seem to move away from the normal data, which is quite noticeable.
