Evaluating Embedding APIs for Information Retrieval
https://arxiv.org/abs/2305.06300
Beginning with models on HuggingFace, numerous embedding models have been released. However, in practical terms, the models that demonstrate high performance are likely those deployed as services by OpenAI, and Aleph-Alpha and Cohere. This paper evaluates these models, which are provided as APIs, using publicly available datasets such as MIRACL.
What points that I am interested in this paper
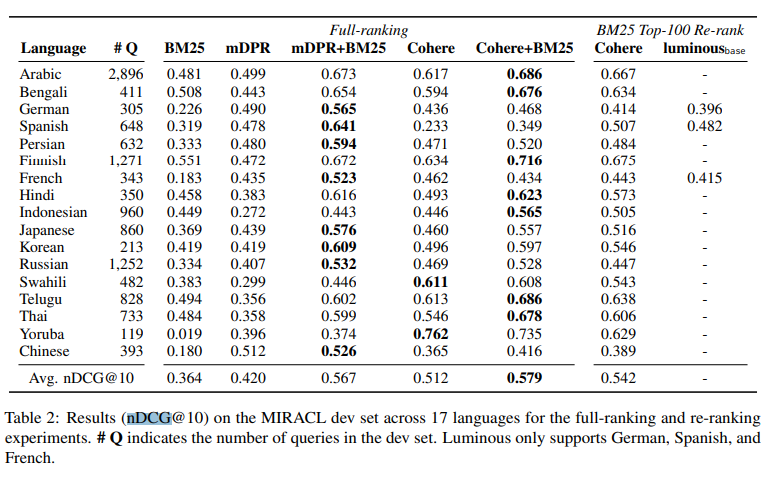
- OpenAI is not considered suitable for non-English datasets, to the point that it is not even included in evaluations. I was somewhat shocked to learn this, as I was unaware of it. However, there are blogs that have published data indicating that OpenAI’s ada-002 model yields not-too-bad results for Japanese, my native language. Therefore, I believe it is necessary to conduct experiments to verify this.
- The performance of the traditional keyword search method, BM25, is not too bad. Personally, while I find the process of embedding search simple and appealing, I often feel that searches based on such simple distance metrics frequently do not function well. This seems likely due to the curse of dimensionality. OpenAI Embeddings are 1500-dimensional, and Cohere’s even reach 4096 dimensions. These feature vectors would likely be more manageable if they were reduced through dimensionality reduction or converted to sparse vectors.
- mDPR
- nDCG